In 2017, a short research paper proposed that language might be handled without reading it in order.
The claim was not presented as a break with what came before. It described a method. Yet it removed a constraint that had shaped how machines processed text for decades.
The paper, titled Attention Is All You Need, was produced by researchers at Google, including Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. It introduced what came to be known as the Transformer model.
Until that point, most systems in natural language processing relied on recurrent neural networks and long short term memory networks. These systems processed words one at a time, moving through a sentence step by step. This made training slow and computationally expensive. It also limited how far a model could carry context. When sentences became long, earlier information was often lost, and relationships between distant words became difficult to maintain.
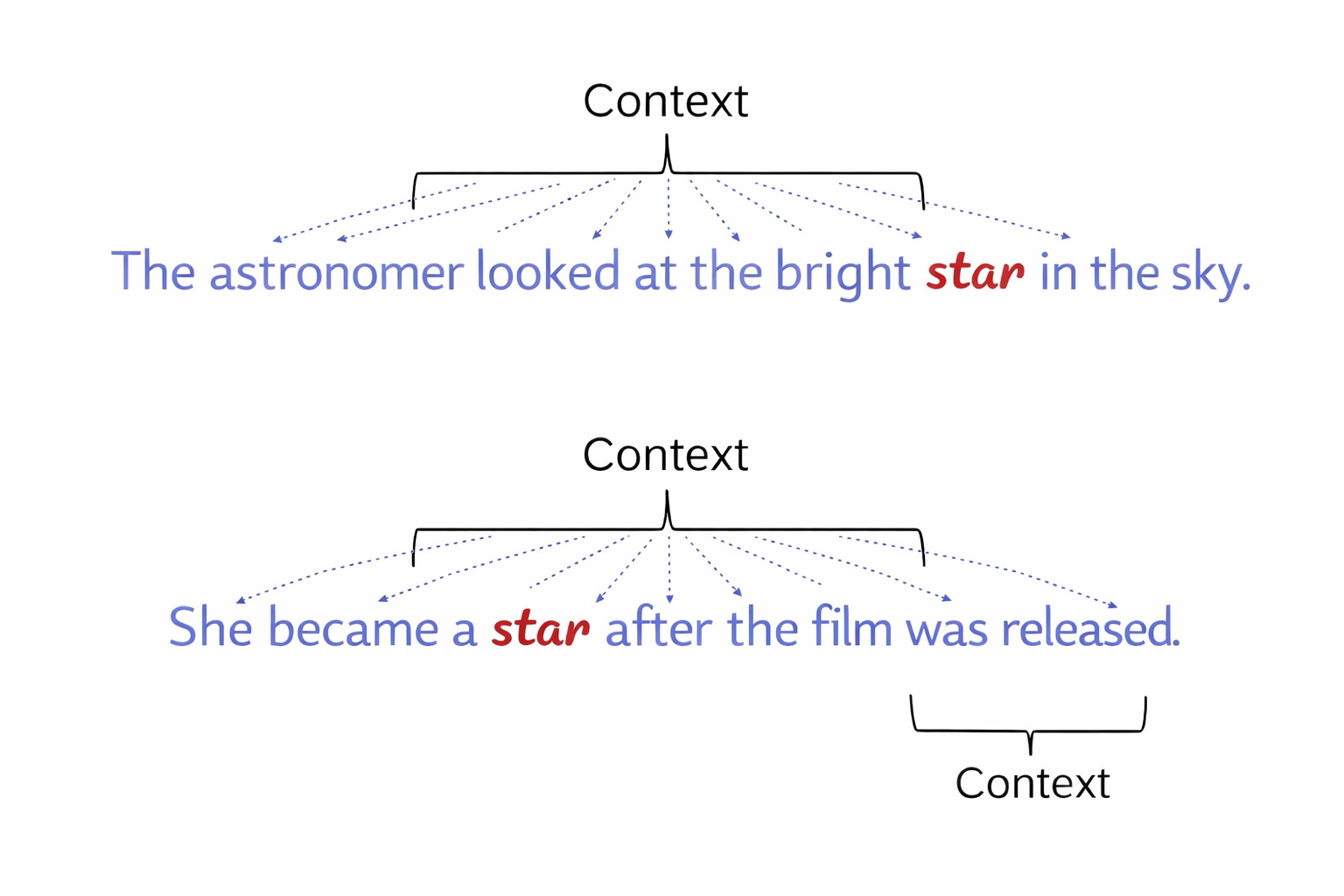
The Transformer model removed the need for this sequential approach. It introduced a mechanism referred to as self attention, which allowed the system to consider all words in a sentence at the same time. Each word could be compared with every other word, and different weights could be assigned to reflect their importance in context. In a sentence such as “The bank approved the loan”, the model could determine whether the word bank referred to a financial institution or a riverbank by considering the surrounding words simultaneously.
This change also allowed for parallel processing. Instead of handling each word in turn, the model could process entire sequences at once, making training faster and more efficient. It also improved the handling of long range dependencies, as context could be retained across the full length of a sentence rather than carried forward step by step.
These changes formed the basis for a new approach to language processing. The impact became clearer in 2018, when Google introduced BERT, short for Bidirectional Encoder Representations from Transformers.
BERT was designed to capture the meaning of words in context by processing text in both directions at once. Earlier models typically read from left to right or from right to left. BERT considered both directions simultaneously, allowing it to interpret words based on the full sentence. In a sentence such as “He went to the bank to withdraw money”, the model could resolve the meaning of the word bank with greater accuracy because it had access to the entire context.
The model was trained using a method known as masked language modelling. Portions of text were removed, and the system was required to predict the missing words based on the surrounding context. This forced the model to learn relationships between words rather than rely on simple patterns. It was also trained to predict whether one sentence followed logically from another, improving its ability to understand longer passages and dialogue.
The effects of these changes became visible in practical applications. Search systems began to interpret queries more accurately, moving beyond simple keyword matching to a broader understanding of intent. Virtual assistants became more responsive to context, producing replies that followed the structure of conversation more closely. Machine translation improved, producing results that were more natural and less rigid.
The Transformer architecture quickly became the foundation for further development. Models designed for text generation built on the same structure. Systems such as GPT-2 in 2019 and GPT-3 in 2020 demonstrated the ability to generate extended passages of text that remained coherent and contextually relevant. By 2022, ChatGPT brought this capability into a conversational form, allowing users to interact directly with a language model.
The same underlying approach has been applied beyond text. Transformer based systems are now used in image generation, music composition and video analysis. Tools such as DALL·E generate images from written prompts, while other systems apply similar methods to different forms of data.
The result is that the Transformer model now underpins much of what is described as modern artificial intelligence. It has become a common architecture across a range of applications, from search engines to customer service systems, from translation tools to creative software. Systems built on this approach are now part of everyday use, shaping how information is accessed and produced.
What began as a change in method has altered how language itself is handled by machines. The ability to process context, nuance and meaning with greater accuracy has reduced the gap between interpretation and generation. Systems are no longer limited to recognising patterns in text. They can produce text that follows those patterns in ways that are often difficult to distinguish from human writing.
The significance of that shift is still being understood. The method did not announce itself as a turning point. It removed a limitation, and the effects have continued to extend outward. The extent to which this changes the relationship between language and computation remains open. What is clear is that the structure introduced in 2017 now sits beneath a large part of how machines read and write.