In 1995, a method appeared that did not attempt to imitate intelligence.
It approached the problem from a different direction. Instead of asking how a system might recognise patterns in the way a person does, it asked how a boundary might be drawn with as much certainty as possible.
The work came from Vladimir Vapnik and Corinna Cortes. The method became known as the Support Vector Machine.
At the time, machine learning was unsettled. Neural networks had shown promise, but they were difficult to train and often unreliable. Many systems required large amounts of data and careful tuning, and even then performance could be inconsistent. There was a need for something more stable, something that could produce strong results without depending on scale.
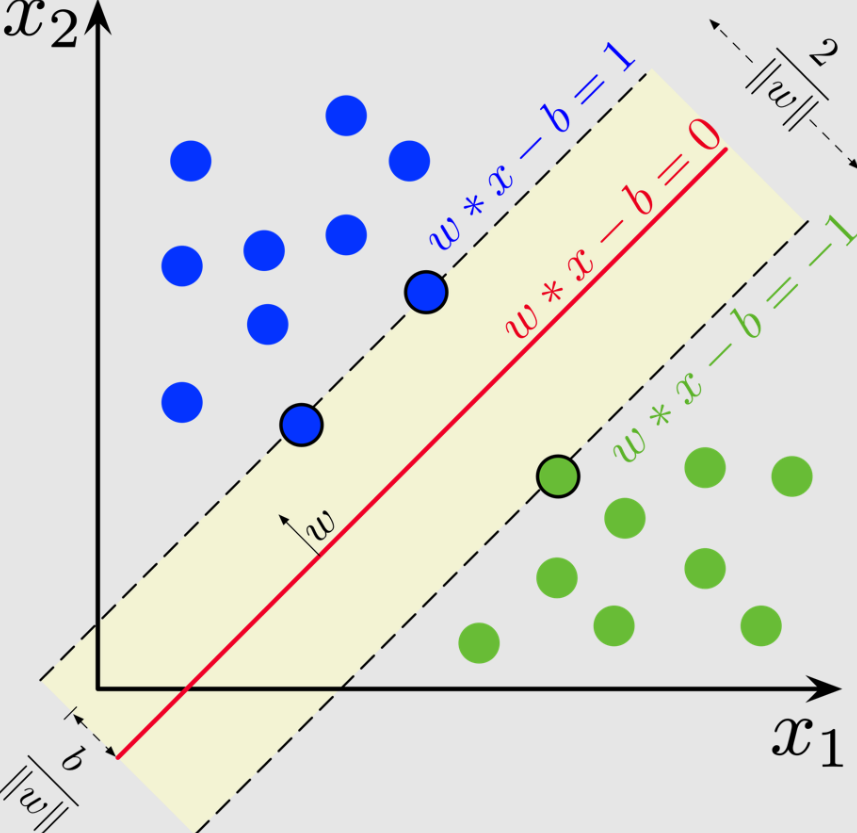
Support Vector Machines addressed that problem by focusing on separation. Given a set of data points belonging to different categories, the aim was to find a boundary that divided them as clearly as possible. In its simplest form, this boundary is a line. In higher dimensions, it becomes a plane. The method did not settle for any dividing line. It searched for the one that maximised the distance between the two groups.
This distance, known as the margin, became the central idea. A wider margin implied a clearer separation and, in turn, a better chance that the model would perform well on new data. Rather than relying on all available points, the system focused on those closest to the boundary. These points, the support vectors, defined the position of the dividing line. The rest of the data could be set aside once the boundary was established.
This approach carried an advantage. By concentrating on the most critical points, the model reduced the risk of overfitting. It did not attempt to accommodate every variation in the data. It aimed instead for a separation that would hold under change.
The method extended beyond simple cases through what became known as the kernel trick. When data could not be separated by a straight line, it could be transformed into a higher dimensional space where separation became possible. This transformation was carried out without explicitly computing the new coordinates, allowing the system to handle more complex structures while remaining computationally efficient.
In practical terms, this allowed Support Vector Machines to perform well in areas where earlier methods struggled. In text classification, they were used to distinguish between categories such as spam and non spam by analysing the presence and arrangement of words. In image recognition, they were applied to tasks such as identifying handwritten digits and detecting features within medical scans. In bioinformatics, they were used to classify genes and analyse protein structures. In finance, they were employed to identify patterns associated with fraud or market behaviour.
These applications shared a common feature. The data was often limited, and the cost of error could be high. In such settings, the ability to produce reliable classifications without requiring vast datasets was of particular value.
The method was not without limitations. Training could become slow as datasets grew larger. The choice of kernel required care, as different transformations could lead to different results. As deep learning developed, systems based on neural networks began to outperform Support Vector Machines in tasks involving large scale data and complex representations, such as speech recognition and image generation.
Even so, the influence of the method remained. It demonstrated that a well defined mathematical approach could produce strong results in practical applications. It contributed to the shift towards treating learning as an optimisation problem, where the objective is to find parameters that satisfy a clear criterion. Concepts such as maximising margins and operating within transformed feature spaces informed later developments, even as the techniques themselves evolved.
Support Vector Machines did not promise to replicate human reasoning. They offered something more precise. They showed that, under certain conditions, the problem of classification could be reduced to the geometry of separation.
That reduction proved sufficient for a wide range of tasks. It also marked a point at which machine learning began to rely less on heuristic construction and more on formal methods that could be analysed, tested and extended. The consequences of that shift are still visible in how models are built today.