In 1986, a method for correcting mistakes began to matter more than the mistakes themselves.
The paper was technical. It did not announce a new machine or a visible system. It described a way of adjusting internal parameters in a network so that errors could be traced back through the structure that produced them. The authors were Geoffrey Hinton, David Rumelhart and Ronald Williams. The method became known as backpropagation.
Neural networks had existed for decades, but by the mid 1970s they had lost favour. Systems with more than one layer could not be trained effectively. There was no reliable way to determine how each connection within the network should be adjusted when an error occurred. Work by critics in the late 1960s had reinforced the view that such models were limited. Research moved instead towards rule based systems and symbolic approaches.
Backpropagation did not introduce the idea of a neural network. It addressed the question that had prevented those networks from developing further. When a system produces an output that differs from the correct result, the difference can be measured. The problem is to determine how much each internal component contributed to that difference.
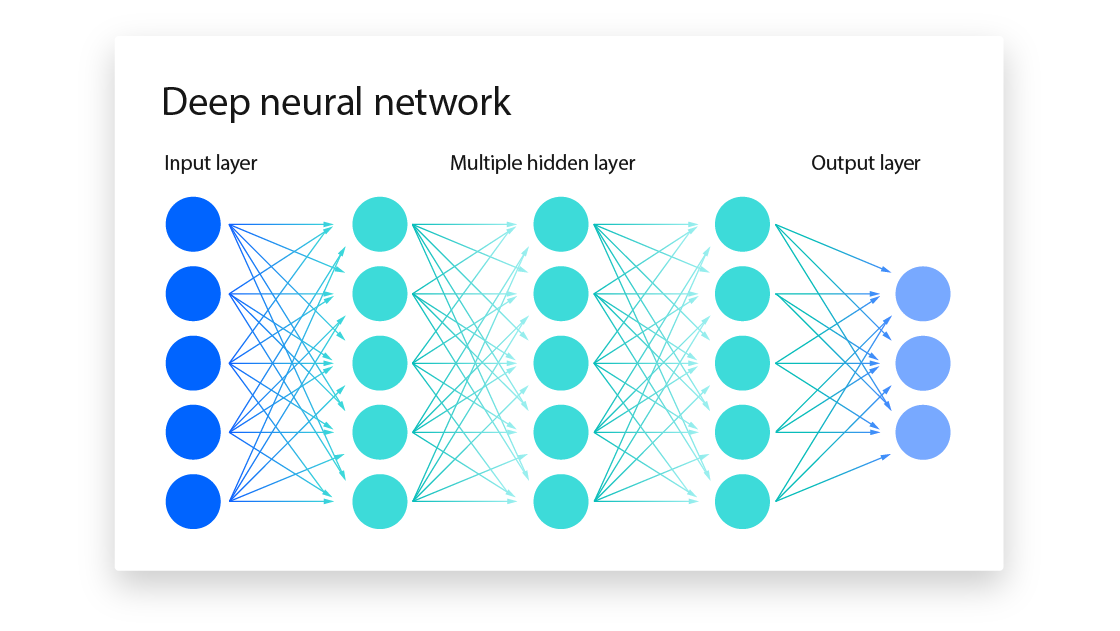
The method proceeds in stages. Data is passed through the network, producing a prediction. This is compared with the correct answer, and the difference is expressed as an error through a loss function. The key step follows. That error is propagated backwards through the network, layer by layer, assigning a share of responsibility to each connection. The weights are then adjusted in the direction that reduces the error. This adjustment is guided by gradient descent, an optimisation process that seeks to move parameters towards a minimum.
The process is repeated across many examples. Over time, the network alters its internal structure in a way that improves its performance. What had previously required manual design becomes a process of adaptation.
The idea was not entirely new. Paul Werbos had described a similar method in 1974, but it had not been widely adopted. The work in 1986 demonstrated that the method could be applied to multi layer networks and could solve problems that earlier approaches could not. It provided a practical procedure, and it showed that networks could learn representations of data that were not explicitly programmed.
The immediate effect was to restore interest in neural networks. They became a viable option for tasks involving pattern recognition. In the years that followed, such systems were used in applications including handwritten digit recognition and early speech processing. These were limited in scale, constrained by available computing power and data, but they established a direction.
The method also introduced a way of thinking about learning. Instead of encoding rules, the system adjusted itself through exposure to examples. The structure remained fixed, but the parameters within it were altered through repeated correction. This approach would later become central to machine learning more broadly.
The limitations were evident. Training required substantial computation, which was difficult to obtain at the time. As networks became deeper, the adjustments applied to earlier layers became smaller, a problem that slowed learning. Large datasets were needed to achieve reliable results, and such data was not always available. These constraints limited the scale at which the method could be applied.
Progress resumed when those constraints began to ease. Increased computing power, particularly through graphics processors, allowed larger models to be trained. New techniques addressed some of the difficulties associated with deeper networks. The growth of the internet provided access to data on a scale that had not previously existed.
When these conditions aligned, the method that had been described in 1986 became central to a new phase of development. Neural networks expanded in depth and complexity. They were applied to image recognition, speech processing and language modelling. Systems that relied on these methods achieved results that exceeded earlier approaches.
The influence of backpropagation is not limited to the systems that use it directly. It established a framework in which learning is treated as an optimisation problem, where performance improves through the adjustment of parameters guided by error. This framework underlies much of modern machine learning.
The paper itself did not resolve all questions about how such systems should be constructed or controlled. It provided a mechanism that made further progress possible. The extent of that progress became clear only later.
The method was, in essence, a way of assigning responsibility. It did not attempt to explain why a system behaved as it did. It made it possible to change that behaviour in a systematic way. That proved sufficient to alter the course of the field.